Reliable, Scalable and Maintainable Applications
Book Overview
Design Data-Intensive Applications by Martin Kleppmann
- Principle and practicality of Data System
- Similarity and difference of data systems
- and their high-level implementations (tradeoffs)
3 parts:
- Foundations of data system
- Reliability, Scalability, Maintainability
- data models and query language
- storage and retrieval
- format of data encoding (serialization) and evolution of schemas
- Distributes data across multiple machines
- replication
- partitioning/sharding
- transaction
- the trouble with distributed system
- consistency and consensus
- Derived data
- batch process
- streaming process
- the features of data system
scalable
highly available (minimizing downtime) and operationally robust
single-node VS distributed systems
online/interactive VS offline/batch processing systems
free and open source software (FOSS)
infrastructure as a service (IaaS) such as Amazon Web Services
Chapter 1: Reliable, Scalable, and Maintainable Applications
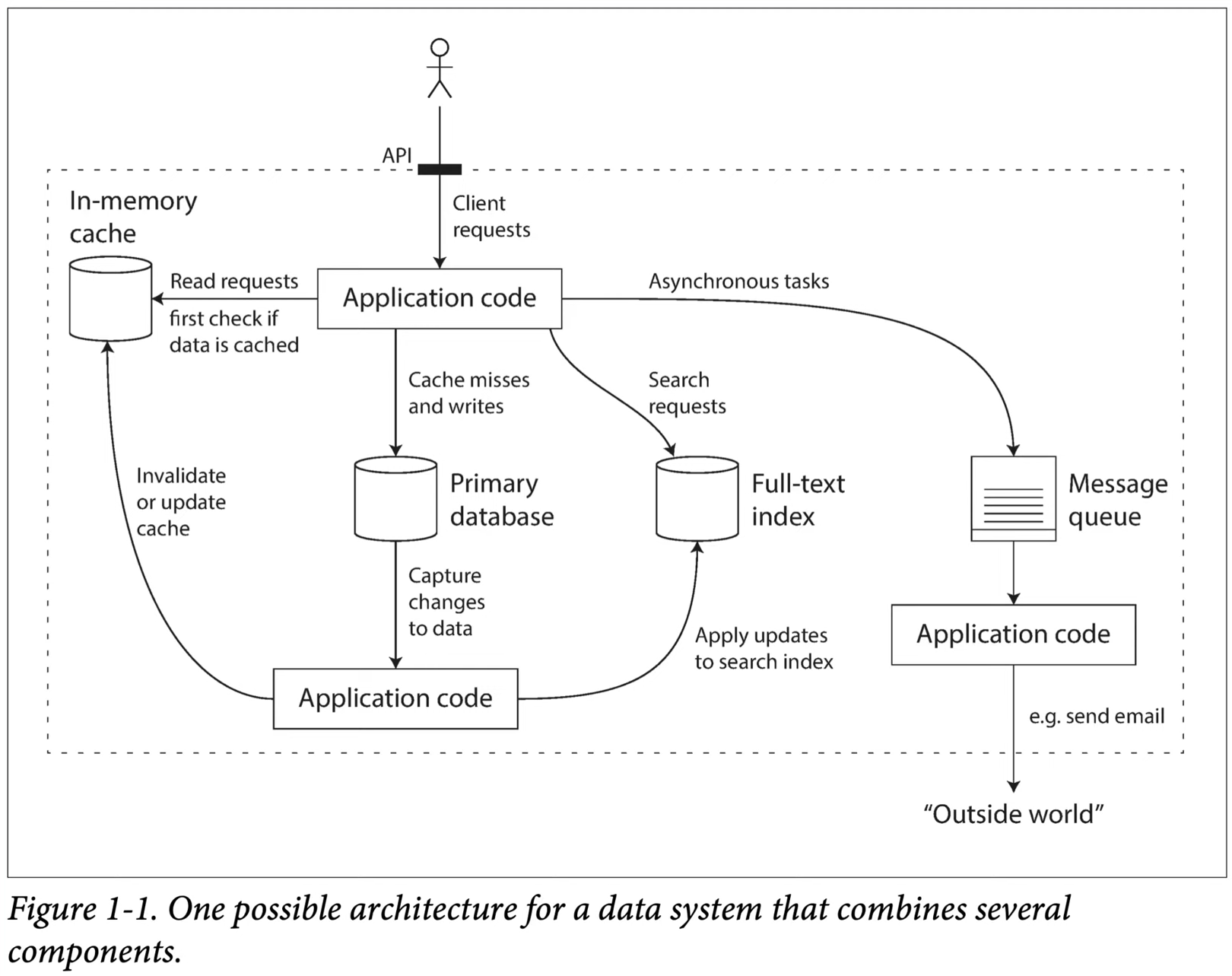
Data System: Database, Cache, Queue, Index
typically built from standard building blocks like:
- database
- caches: Remember the result of an expensive operation, to speed up reads
- search indexes: Allow users to search data by keyword or filter it in various ways
- stream processing: Send a message to another process, or be handled asynchronously
- batch processing: Periodically crunch a large amount of accumulated data
reliable, scalable, and maintainable data systems
- Reliability: System should continue to work correctly even in face of adversity (hardware or software faults, and even human error).
- Scalability: As the system grows (in data volume, traffic volume, or complexity), there should be reasonable ways of dealing with that growth.
- Maintainability: Over time, different people will work on the system maintaining and adapting the system, and they should all be able to work on it productively.
Reliability
continue to work correctly, even when things go wrong
work correctly:
- Function as expected
- Tolerate User Error
- Good Performance
- Under expected load and data volume
- Prevent Bad Actor
- Unauthorized access and abuse
faults -> fault-tolerant or resilient
Tolerate Faults, Prevent Failure
- Hardware faults
- Software errors
- Bugs causing crash
- Resource hungry process
- Dependency error
- the 3rd party api isn’t working
- A service that the system depends on that slows down
- Cascading failure: some service related to it fails
- Human errors
- Configuration error
Deal with Faults
-
Hardware faults
- Redundancy (hardware)
- redundancy of hardware components
- multi-machine redundancy
- to ensure backup machines and data
- When one component dies, the redundant component can take its place while the broken component is replaced.
- Rolling update (software)
- Redundancy (hardware)
-
Software error
- Careful reasoning
- Thorough testing
- Process isolation
- Allow crash and restart
- Measuring/monitoring/analyzing system behavior in production
- sending alert if a discrepancy is found
-
Human Error
- Minimize opportunities for error through abstraction and interface sandbox
- Use “design patterns” to structure the system well
- eg. facade
- Unit test, integration test, manual test
- Quick recovery
- make it fast to roll back configuration changes
- roll out new code gradually
- Monitoring
- performance metrics and error rates
- Management
- Minimize opportunities for error through abstraction and interface sandbox
Scalability
a system’s ability to cope with increased load
How to quantify “scalability”?
- Load
- volume of read/write
- volume & complexity of data
- response time
- access pattern
- Performance
- throughput
- the number of records we can process per second
- response time
- what the client sees
- service time + network delays + queuing delays
- varies on every try
- latency
- the duration that a request is waiting to be handled
- throughput
twitter’s example
Maintainability
- Operability
Make it easy for operations teams to keep the system running smoothly- Monitoring, recovering, root-causing
- Patching and updating
- Capacity planning
- Best practice deploying
- Security
- Define process (write clear docs)
- Maintain knowledge base
- Simplicity
Make it easy for new engineers to understand the system- Accidental complexity
- Explosion of state space
- Tight coupling
- Tangled dependency
- Special casing
- Accidental complexity
- Evolvability: agility on a data system level
Make it easy for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change- Easy to make change
- New facts
- Unanticipated use cases
- Business priority shift
- New feature
- New platform
- Legal requirements
- Growth of system
Maintainable Data System
- Operability
- Good monitoring
- Avoid dependency
- Good documentation
- Good default & options
- Self-healing & control
- Predicable
- Simplicity
- Good abstraction (design patterns)
- Evolvability
- Agile
Requirements
- functional requirements: what it should do
- allowing data to be stored, retrieved, searched, and processed
- nonfunctional requirements
- security, reliability, compliance, compatibility, maintainability
Reference
- Martin Kleppmann, Designing Data-Intensive Applications ↩
- 精读DDIA 第一章 Reliable, Scalable and Maintainable Applications, https://youtu.be/HBuAklMAjaA ↩
- DDIA 逐章精读(1), https://ddia.qtmuniao.com/#/ch01 ↩
DDIA Chapter1 Notes
https://ruijun-ni.github.io/blog/2022/10/27/DDIA/DDIA-Chapter1/